EXPLORA: Efficient Exemplar Subset Selection for Complex Reasoning
Abstract
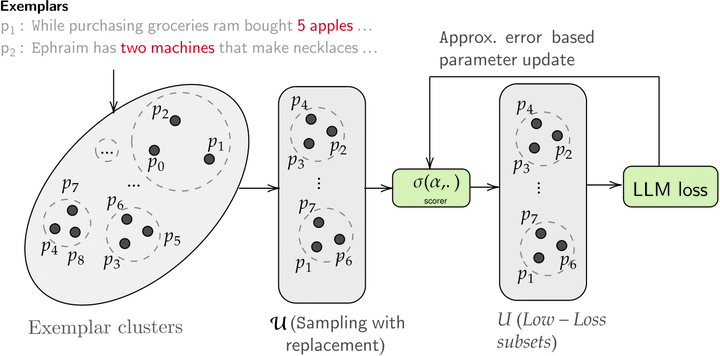
Answering reasoning-based complex questions over text and hybrid sources, including tables, is a challenging task. Recent advances in large language models (LLMs) have enabled in-context learning (ICL), allowing LLMs to acquire proficiency in a specific task using only a few demonstration samples (exemplars). A critical challenge in ICL is the selection of effective exemplars, which can be either task-specific (static) or test-example-specific (dynamic). Static exemplars provide faster inference times and increased robustness across a distribution of test examples. In this paper, we propose an algorithm for static exemplar subset selection for complex reasoning tasks. We introduce EXPLORA, a novel exploration method designed to estimate the parameters of the scoring function, which evaluates exemplar subsets without incorporating confidence information. EXPLORA significantly reduces the number of LLM calls to ~11% of those required by state-of-the-art methods and achieves a substantial performance improvement of 12.24%. We open-source our code and data (https://github.com/kiranpurohit/EXPLORA).